วิธีการทำงานของ web browser
HTML, CSS กับ JavaScript เป็น 3 องค์ประกอบหลักของเว็บไซต์ทั่วๆ ไปที่เราเห็นกันอยู่ ส่วน web browser นั้นก็มีหน้าที่แปลง code ของทั้ง 3 ส่วนประกอบนั้น แสดงผลออกมาเป็นเว็บไซต์ให้เราได้ใช้งาน
ในฐานะคนทำเว็บ ผมคิดว่าการทำความเข้าใจหลักการทำงานของ web browser นั้นช่วยให้เข้าใจถึงที่มาที่ไปของสิ่งที่ปรากฏบนหน้าจอ รวมถึงจะเป็นประโยชน์ในเรื่องการ optimize performance ของเว็บไซต์ด้วยครับ
ในโพสต์นี้จะขอข้ามเรื่อง network connection ไป แต่จะเริ่มตั้งแต่การทำงานของ web browser
หลังจากได้รับ response เป็น code จาก server ไปจนถึงขั้นตอนสุดท้ายคือตัวเว็บไปปรากฏบนหน้าจอ
หรือพูดง่ายๆ ก็คือ ตั้งแต่ browser ได้รับ code <html><head></head>...</html> จนถึงขั้นตอนการ render เว็บจ้า
browser แต่ละตัวจะมีส่วนที่ทำหน้าที่แสดงผลเว็บไซต์ ที่เรียกว่า rendering engine หรือ layout engine เช่น
- Blink (Chrome, Opera)
- Gecko (Firefox)
- WebKit (Safari/Modern Edge)
- EdgeHTML (Edge)
- Trident (Internet Explorer)
rendering engine แต่ละตัวก็มีวิธีการแสดงผลที่แตกต่างกันในรายละเอียดเชิงลึก และคำศัพท์เฉพาะที่แต่ละ engine ใช้เรียกแต่ละขั้นตอน แต่ภาพรวมแล้วขั้นตอนจะคล้ายกัน เป็นไปตาม spec ของ W3C ซึ่งขั้นตอนหลักๆ มีอยู่ ดังนี้
1. การสร้าง DOM กับ CSSOM
DOM (Document Object Model) คือตัวแสดงคุณสมบัติและความสัมพันธ์ระหว่างแต่ละ object ในหน้าเว็บ (document) ซึ่งก็จะประกอบไปด้วย properties กับ methods ของแต่ละ object พร้อมกับความสัมพันธ์กับ object อื่นๆ เช่น object A เป็น parent ของ object B และขณะเดียวกันก็ทำให้ object B เป็น child ของ object A เช่นกัน
ส่วน CSSOM (CSS Object Model) นั้นก็เช่นเดียวกับ DOM แต่เป็นการสร้าง object model จาก CSS ของเว็บ ที่มีทั้ง properties ที่เราคุ้นเคยกันใน CSS พร้อมกับความสัมพันธ์กับ object อื่นๆ ซึ่งก็คือคุณสมบัติ cascading ของ CSS ครับ
การสร้าง object จาก code ที่ได้รับมาจาก server นั้น จะประกอบด้วย 2 ขั้นตอนย่อยคือ Tokenization กับ Parsing
Tokenization (Lexical Analysis)
Tokenization ในโลก DOM คือกระบวนการที่บอกว่า code แต่ละตัว หรือแต่ละช่วงนั้น มันคือส่วนประกอบใดของ element
ตาม spec ของ W3C ตัวอย่างเช่น เรามี <button>Go</button> ซึ่งถือเป็น 1 element
กระบวนการ tokenization คือการระบุว่า
<button>คือ tag เปิดGคือ characteroคือ character</button>คือ tag ปิดของ element นี้
นั่นคือการระบุแต่ละส่วนของ code ออกมาเป็น token แยกออกเป็นตามประเภท นั่นเอง
Parsing (Syntactic Analysis)
Parsing คือการนำ token แต่ละส่วนที่ได้จากขั้นตอน tokenization นำมาตรวจสอบกับ HTML syntax ว่ามีความหมายอย่างไร และต้องเป็น object ชนิดไหน จากนั้นจึงสร้างเป็น object ซึ่งในโลกเว็บก็คือ DOM node กับ CSSOM node นั่นเอง แต่ละ node ก็ประกอบด้วย property (attribute) กับ method ของ object นั้นๆ และ object ที่ได้เหล่านี้ก็จะถูกนำไปประกอบกับเป็น tree structure ขึ้นมา
DOM & CSSOM Tree construction
หลังจากที่เราได้ node แล้ว ก็มาถึงขั้นตอนการเชื่อมความสัมพันธ์ระหว่าง node นั่นคือการบอกว่า node ไหน เป็น parent/child ของ node ไหน ซึ่งพอเราเชื่อมทุก node เข้าด้วยกัน ก็จะได้โครงสร้างที่เป็น tree ของ node ขึ้นมา เรียกว่า DOM Tree กับ CSSOM Tree ครับ
สำหรับ DOM นั้นจะค่อนข้างชัดเจน อย่างที่เห็นใน code หรือ element inspector ใน DevTools
<html>
<head>
<title>Awesome</title>
</head>
<body>
<h1>Hi</h1>
</body>
</html>DOM tree ก็จะออกมาแบบนี้

แต่ CSSOM นั้น ไม่มีโครงสร้างชัดเจนเหมือน DOM แต่ก็มีโครงสร้างเป็น tree เหมือนกัน
นั่นก็เพราะว่า CSS มีคุณสมบัติ cascading ที่ style ของ element บางส่วนจะ inherit มาจาก parent element
และทุก element ก็จะ inherit style ของ <body> และ <html> มาเช่นกัน
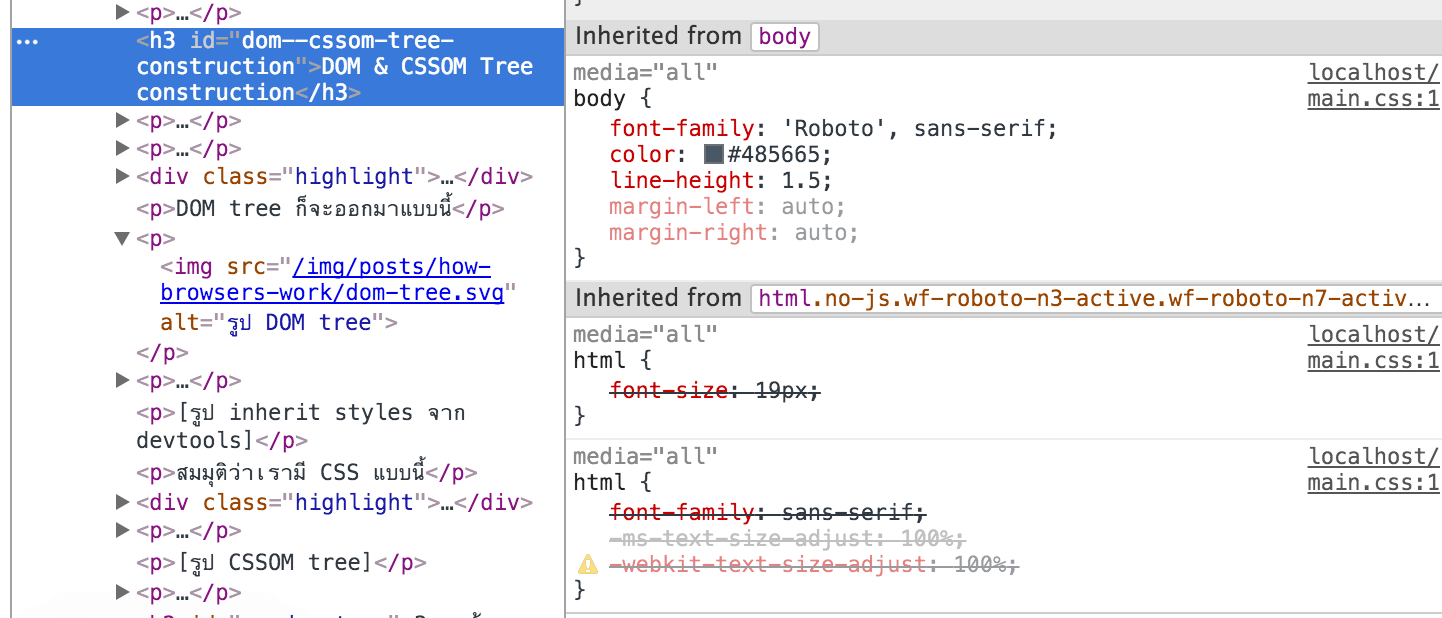
สมมุติว่าเรามี CSS แบบนี้
div { ... }
p { ... }
div p { ... }CSSOM tree ก็จะออกมาประมาณนี้ครับ สังเกตว่าแท็ก <p> ปรากฎอยู่ใน CSSOM tree 2 ที่ด้วยกัน
style ที่แท็ก <p> แต่ละตัวจะได้รับ ก็ต่างกันไปตามโครงสร้างของ CSSOM tree
และจะถูกนำไปใช้ในขั้นตอนการ render ต่อไปครับ

หลังจากที่ได้ DOM Tree กับ CSSOM Tree แล้ว ก็จะถึงขั้นตอนต่อไปที่การสร้าง Render Tree
2. สร้าง Render Tree
Render tree ถูกสร้างขึ้นมาจาก DOM tree และ CSSOM tree โดยที่ render tree จะประกอบด้วย DOM element ที่จะถูก render บนหน้าจอ browser เท่านั้น ดังนั้นจะมีบาง element ที่อยู่ใน DOM tree แต่ไม่อยู่ใน render tree คือ:
- element
<head>และ element อื่นๆ ข้างใน - element
<script> - element ที่มี style
display: noneกำหนดไว้อยู่
แต่ละ node ใน DOM tree ก็จะได้รับ style ต่างๆ จาก node ใน CSSOM tree ประกอบกันได้ render tree ขึ้นมาครับ
3. Layout
Layout หรือ Reflow คือการที่ browser คำนวนหาขนาดและที่อยู่ของ element ใน render tree
ขนาดของ element ประกอบไปด้วย width กับ height ส่วนที่อยู่ตำแหน่งของ element นั้น
เป็นระบบ coordinate (x,y) ว่าอยู่ตรงไหนเทียบกับหน้าจอ (viewport) ซึ่งเป็น root element ใน render tree
ในขั้นตอนนี้ style ที่กำหนดตำแหน่งของ element จะถูกแปลงเป็นหน่วย absolute pixel เมื่อเทียบกับ viewport
เช่น “<div id="logo"> อยู่ที่ตำแหน่ง 10px จากด้านซ้าย และ 5px ด้านบน เมื่อเทียบกับ viewport” เป็นต้น
ด้านล่างนี้เป็นวิดีโอจำลองการ reflow ของ Gecko engine ของ Firefox กับเพจ mozilla.org [ที่มา]
4. Paint
Paint คือการ render แต่ละ element ใน render tree ออกมาเป็นแต่ละ pixel ให้ไปปรากฎอยู่บนหน้าจอ browser ซึ่งขั้นตอนการใส่แต่ละ property ให้แต่ละ element ก็จะประกอบไปด้วยขั้นตอนยิบย่อยที่ browser ต้องทำอีกมากมาย ส่วนมากมักเป็นการ “วาด” ส่วนประกอบต่างๆ ออกมาบนหน้าจอ พอ render ครบทุก element ก็จะได้เป็นเว็บออกมาครับ
ขั้นตอนเหล่านี้ไม่เกิดขึ้นเพียงครั้งเดียวแล้วก็จบไป แต่อาจเกิดขึ้นได้หลายๆ ครั้ง เช่น กรณีที่ DOM ถูกอัพเดท หรือการแก้ไข CSS property บางอย่างของ DOM element ก็ทำให้เกิด Layou/Paint ได้ครับ ดูเพิ่มได้ที่ csstriggers.com ได้เลยจ้า
ทั้งหมดนี้ก็เป็นขั้นตอนคร่าวๆ ของวิธีการแสดงผลเว็บไซต์ของ web browser ที่เราใช้กันอยู่ในปัจจุบัน จะเห็นว่า web browser ที่ทำหน้าที่แสดงผลเว็บไซต์ นั้นจริงๆ แล้วมีขั้นตอนการทำงานที่ค่อนข้างซับซ้อนพอสมควร แต่การทำความเข้าใจเรื่องเกี่ยวกับ browser ก็ถือเป็นพื้นฐานที่สำคัญที่จะต่อยอดไปเรียนรู้เรื่องอื่นๆ ต่อได้ครับ
Sources / อ่านเพิ่ม
- How Browsers Work: Behind the scenes of modern web browsers HTML5Rocks
- How Browser Works (slides) by Arvind Ravulavaru
- Life of a Button Element (video) by Alex Russell
- An overview of Lexing and Parsing by Ron Savage
Related posts